
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Selective Vectorization for Short-Vector InstructionsSamuel Larsen, Rodric Rabbah & Saman AmarasingheIntroductionToday's microprocessor designers have a wealth of transistors they can employ for innovative architectural features. An important example is the multimedia extensions in today's general-purpose and embedded processors. Examples include VIS, MAX-2, MMX, 3DNow!, SSE, SSE2, and VMX/AltiVec. These extensions represent one of the biggest advances in general-purpose processor architecture in the past decade. If used efficiently, they present an opportunity for large performance gains. Before multimedia extensions can become generally useful to the computing community, however, their use must be completely transparent to the high-level programmer. Toward this end, we have developed compiler techniques that automatically target the primary component in multimedia extensions: short-vector instructions. Existing ApproachesIn order to obtain the best performance, an effective compiler must utilize the target architecture's resource set as efficiently as possible. General-purpose processors normally exploit instruction-level parallelism, or ILP. Therefore, one approach to optimizing data-parallel loops is to use an ILP technique, such as software pipelining. Unfortunately, without explicit instruction selection to vectorize operations, software pipelining cannot utilize a processor's vector processing capabilities. An alternative approach is to directly adopt compiler technology developed for vector supercomputers. Traditional vectorization, however, is not well-suited for compilation to multimedia extensions, and can actually lead to a performance degradation. The primary cause for poor performance is the compiler's failure to account for an architectures's scalar processing capabilities. When loops contain a mix of vectorizable and non-vectorizable operations, the conventional approach distributes a loop into vector and scalar portions, destroying ILP and stifling the processor's ability to provide high performance. A traditional vectorizing compiler also vectorizes as many operations as possible. This approach is problematic for general-purpose processors which, in contrast to vector supercomputers, do not devote the vast majority of resources to vector execution. On today's general-purpose designs, full vectorization may leave a significant fraction of the processor's execution units underutilized. Selective VectorizationFigure 1 shows the low-level data dependence graph for the main loop in tomcatv, an application from the SPEC CFP95 benchmark suite. The loop accounts for roughly 50% of the benchmark's total execution time. For clarity, the figure omits address calculations and loop control operations. Suppose we wish to compile the loop for execution on an architecture providing 2 memory units, 2 scalar floating-point units, 1 vector floating-point unit, and sufficient ALU units to handle address calculations. With software pipelining, loop performance is limited by the number of floating-point units. Assuming single-cycle throughput for all operations, each loop iteration requires 23 cycles to execute the 46 floating-point operations.
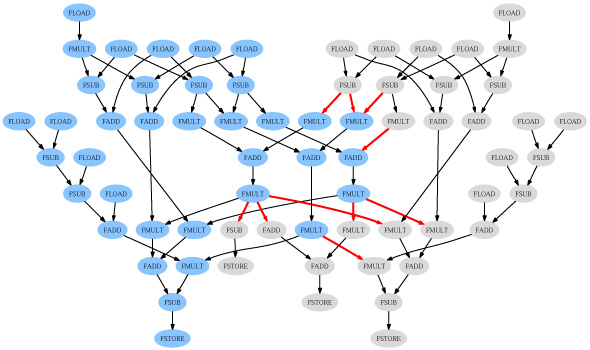
Figure 1: Data dependence graph for the main loop in tomcatv. As an alternative to a strictly ILP-based approach, we might choose to vectorize the loop. An absence of dependence cycles means the loop is fully vectorizable. A traditional vectorizing compiler would replace all operations in Figure 1 with the corresponding vector instructions. We could then software pipeline the vector loop to mask vector operation latency. A single vector unit requires 46 cycles to execute the 46 floating-point operations. Assuming a vector length of 2, one iteration of the vector loop executes two iterations of the original loop. As a result, traditional vectorization combined with software pipelining requires an average of 23 cycles per iteration, matching the performance of software pipelining alone. With both techniques, a large portion of the machine's execution resources are underutilized. We propose to target the processor's vector and scalar resources simultaneously in order to achieve the best performance. We call this technique selective vectorization since it performs vectorization only where it is profitable. We have developed an effective selective vectorization algorithm [1] based on a two-cluster partitioning heuristic [2,3]. In Figure 1, highlighted nodes represent those chosen for vectorization using our technique. This partition requires 26 cycles to execute each vector iteration, reduced from 46 cycles, and represents a speedup of 1.77x over competing techniques. An important aspect of our approach is its ability to accommodate dataflow between vector and scalar operations. Most contemporary multimedia extensions implement separate vector and scalar register files; transferring data between the register files requires explicit operations. In most cases, the processor provides no underlying support and we must transfer data through memory using a series of load and store instructions. In Figure 1, highlighted edges show where the compiler must insert explicit communication. In generating this partition, selective vectorization assumed no hardware support for operand transfer. Despite the high cost, the technique achieves a significant performance improvement. ResultsWe evaluated selective vectorization on a set of SPEC FP benchmarks for a realistic VLIW architecture. Figure 2 shows the speedup of traditional vectorization and selective vectorization over software pipelining. For several benchmarks, the traditional approach leads to a loss in performance. In contrast, selective vectorization outperforms the other techniques in all benchmarks. In the best case, the technique achieves a whole-program speedup of 1.35x.
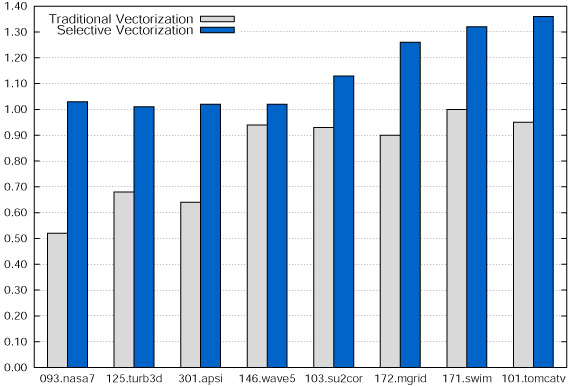
Figure 2: Speedup of traditional and selective vectorization over software pipelining. References[1] Samuel Larsen, Rodric Rabbah, and Saman Amarasinghe. Exploiting Vector Parallelism in Software Pipelined Loops. In Proceedings of the 38th International Symposium on Microarchitecture, Barcelona, Spain, Nov. 2005. [2] C.M. Fiduccia and R.M. Mattheyses. A Linear-Time Heuristic for Improving Network Partitions. In Proceedings of the 19th Conference on Design Automation, pages 175-181, 1982. [3] B.W. Kernighan and S. Lin. An Efficient Heuristic Procedure for Partitioning Graphs. Bell System Technical Journal, 49:291-307, February 1970. |
|||
|