
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Collaborative CompilationMark Stephenson, Ben Wagner & Saman AmarasingheMotivationRecently, researchers have applied machine learning techniques to automatically craft compiler heuristics. While their techniques have proved to be successful, all previous machine learning researchers have relied on "at-the-factory" training, which builds a compiler to perform well on a repertoire of applications (and input data sets) that the compiler developer thinks is representative of the applications that a typical user might run. One major drawback of this approach is that the machine learning algorithm may actually hinder the performance of applications that were not in the developer's training set. Another shortcoming of prior research is the difficulty of obtaining data sets that are large enough to adequately train a machine learning algorithm. ApproachThis abstract presents collaborative compilation, which enables ordinary users to transparently extract machine learning training data by simply running their compiler as they normally would. Collaborative compilation instruments a fraction of the methods in a user's application to automatically extract the data necessary to train a machine learning algorithm. We show that the small overhead due to method instrumentation is more than offset by the potential gains of training a learning algorithm to run well on the applications that the user typically runs. As the name suggests, collaborative compilation is a community endeavor; collaborative users are granted access to the community on the condition that they contribute their instrumentation data (see Figure 1). We prototype our collaborative compiler in the Just-In-Time (JIT) compiler of a Java Virtual Machine, which offers two main advantages:
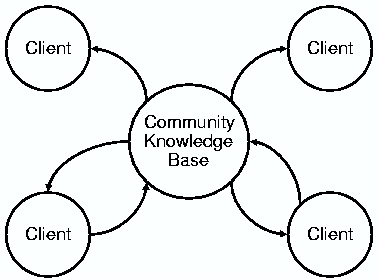
Figure 1. Collaborative clients consult the community knowledge base for the latest-and-greatest compiler heuristics. In addition a small portion of a client's methods are instrumented to collect additional data, which is contributed to the knowledge base. To automatically, and transparently create a data set that is suitable for training a machine learning algorithm (via supervised learning, for instance), our system has to be able to determine the cases in which one optimization is better another. For example, let's assume we are comparing optimization policy A against policy B. A collaborative compiler would insert instrumentation code on the fly that compares these two policies. The instrumentation code essentially creates two pairs of methods (four total methods) for each method that has been selected for collaborative instrumentation. Two of the methods are optimized with policy A, and the other two are optimized with policy B. The redundant methods of a given version allows us to detect outliers. We compared thousands of identical methods (policy A = policy B) using the approach described above. Because the methods are identical, we expect the runtime ratio (i.e., how much faster one version is than the other) to be 1. We find that by applying our techniques, 89% of the samples are within 3% of 1 (without our techniques only 64% of the samples are within the 3% tolerance). This result is encouraging. Preliminary ResultsFor our preliminary results we aggregate a giant database of method-specific runtime information. By using the runtime information in the database to make compilation decisions we can attain significant speedups. Figure 2 shows the improvement in steady state performance for the Java benchmarks in the DaCapo benchmark suite. We only slow down one benchmark, and we achieve up to a 16% improvement. The black bars show the input data set that was used to populate the database, and the red bars represent an alternate data set. Remember, the training process simply requires the user to run the benchmarks in which he is interested. For more information, please see: http://www.cag.csail.mit.edu/metaopt 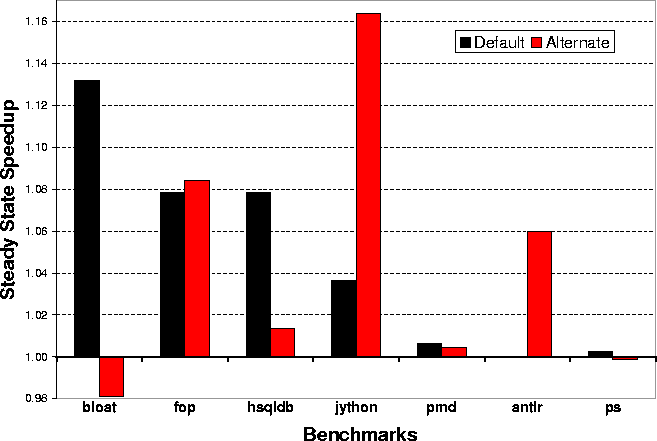 Figure 2. Steady state performance. References:[1] Mark Stephenson, Ben Wagner, and Saman Amarasinghe. Collaborative Compilation. Currently in Submission, Click here for a Technical Report. |
|||
|