
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
A Sinusoidal Model Approach to Acoustic Landmark Detection and Segmentation for Robust Segment-Based Speech RecognitionTara N. Sainath & Timothy J. HazenBelow, we present a noise robust landmark detection and segmentation algorithm using a sinusoidal model representation of speech. We compare the performance of our approach under noisy conditions against two segmentation methods used in the SUMMIT segment-based speech recognizer, a full segmentation approach and an approach that detects segment boundaries based on spectral change. The word error rate of the spectral change segmentation method degrades rapidly in the presence of noise, while the sinusoidal and full segmentation models degrade more gracefully. However, the full segmentation method requires the largest computation time of the three approaches. We find that our new algorithm provides the best tradeoff between word accuracy and computation time of the three methods. IntroductionHidden Markov Models (HMMs) have been the most dominant frame-based acoustic modeling technique for automatic speech recognition tasks to date. However, alternative models, such as segment-based models, have been developed to address the limitations of HMMs [1]. For example, the SUMMIT speech recognizer uses a segment-based framework for acoustic modeling [2]. This system computes a temporal sequence of frame-based feature vectors from the speech signal, and performs spectral energy change based landmark detection. These landmarks are then connected together to form a graph of possible segmentations of the utterance. In recent years, improvements in speech recognition systems have resulted in high performance on specific tasks under clean conditions. However, the performance of these systems can rapidly degrade in noisy environments. Likewise, we have discovered that the spectral change segmentation algorithm used in SUMMIT performs poorly in the presence of strong background noises and non-speech sounds. We have observed that noise robustness in SUMMIT can be improved using a full segmentation method. This technique places landmarks at equally spaced intervals and outputs a segment graph which fully interconnects all landmarks. While this approach is computationally more expensive than the spectral segmentation method, it is more robust under noisy environments. To address the limitations of the spectral change and full segmentation methods, we have developed a new landmark detection and segmentation algorithm from the behavior of sinusoidal components generated from McAulay-Quatieri Sinusoidal Model [3]. Our goal is the development of a robust method which improves upon the word error rate of the spectral segmentation method while providing faster computation time than the full segmentation method. Landmark Detection and Segmentation AlgorithmThe McAulay-Quatieri (MQ) Algorithm [3] assumes that speech waveform can be represented by a collection of sinusoidal components of arbitrary amplitudes, frequencies and phases. In voiced regions, these sinusoidal components appear to be smooth and slowly varying, with the births and deaths of these components typically occuring at phoneme transitions. However, in unvoiced regions the sinusoidal tracks are very short in duration and rapidly fluctuate. The sinusoidal births and deaths often occur too frequently and randomly to signal a phonetic transition. Short-time energy and harmonicity are two methods to distinguished between voiced and unvoiced speech segments. Because only sinusoids in voiced regions are useful for landmark detection, we first separate our signal into voiced and unvoiced regions using a combination of these two measurements. In voiced regions, we hypothesize phonetic landmarks by examining a set of features found useful for landmark detection. The most useful features are the number of harmonically related sinusoids that are born or die within a set frame interval (see [4] for details). Since sinusoidal births and deaths occur too frequently to indicate phonetic transitions in unvoiced regions, we decided to place landmarks at a fixed frame interval. After landmarks are detected, an explicit segmentation phase is used to interconnect these landmarks to form a network of hypothetical segmentations. To minimize landmark interconnections, we label the subset of voicing landmarks which signal a voicing change as major landmarks. Furthermore, we reclassify these major voicing landmarks as hard major or soft major landmarks based on the energy difference across the landmark. All other predicted landmarks within voiced and unvoiced regions are termed minor landmarks. In [4] we detail various methods for connecting major and minor landmarks. ExperimentsOur recognition experiments draw from two distinct corpora. The AV-TIMIT corpus is a collection of speech recordings developed for research in audio-visual speech recognition [5]. We simulate noisy speech by adding noise from the Noisex-92 database [6] to clean AV-TIMIT utterances. We also performed experiments using the AURORA 2 database [7], which consists of clean TI-digit utterances to which noise has artifically been added. To observe the tradeoff between word error rate and computation time for the three methods, we compute both statistics as we vary the Viterbi pruning threshold which minimizes the number of possible paths at each step in the recognition search. Figures 1 and 2 illustrate this tradeoff as the pruning threshold is varied for the AV-TIMIT and Aurora tasks. When the computation time is large, the sinusoidal and full segmentation approaches have a significantly lower word error rate than the spectral segmentation method. As the computation time is decreased, the word error rate of the full segmentation method increases sooner than the sinusoidal model approach. Finally, when the word error rate is high for all three methods, the sinusoidal model and spectral segmentation methods offer a much faster computation time than the full segmentation method. Thus, the sinusoidal model provides the best tradeoff between accuracy and computation time under all noise conditions. 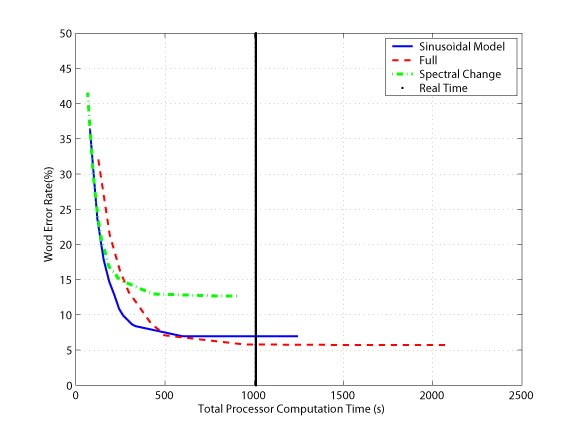 Figure 1: Word error rate vs. computation time for spectral, full and sinusoidal methods on the AV-TIMIT corpus averaged over the 3 noise conditions at a SNR of 5dB.
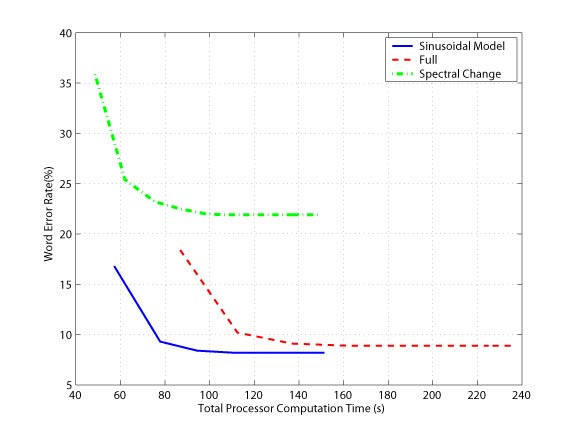 Figure 2: Word error rate vs. computation time for spectral, full and sinusoidal methods on the Aurora 2 corpus averaged over the 4 noise conditions at a SNR of 10dB. ConclusionsIn this work, we explored a landmark detection and segmentation algorithm using a sinusoidal model. We found that our method offered the best tradeoff between word error rate and recognition computation compared to the spectral and full segmentation methods when used within the SUMMIT segment-based recognition system. We would like to expand this work in a number of areas in the future. For example, we would like to observe the performance of the sinusoidal model in realistic environments which may contain a variety of background speech and non-speech sounds. First, we would like to examine the behavior of sinusoidal tracks under different noise conditions to see if we can classify acoustic regions into different sound classes. Secondly, overlapping sounds from difference sources might correspond to different sinusoidal tracks. We would like to explore the use of source separation techniques based on the sinusoidal model as a potential means of improving the robustness of our acoustic models via speech enhancement. References[1] M. Ostendorf, V. Digalakis, and O. Kimball, "From HMMs to Segment Models: A Unified View of Stochastic Modeling for Speech Recognition," IEEE Transactions on Speech and Audio Proceesing, vol. 4, no. 5, pp. 360-378, September 1996. [2] J. Glass, "A Probabilistic Framework for Segment-Based Speech Recognition," Computer Speech and Language, vol. 17, pp. 137-152, 2003. [3] R.J. McAulay and T.F. Quatieri, "Speech Analysis/Synthesis Based on a Sinusoidal Representation," IEEE Transactions on Acoustics, Speech and Signal Processing, vol. ASSP-34, no. 4, August 1986. [4] T.N. Sainath, "Acoustic Landmark Detection and Segmentation Using the McAulay-Quateiri Sinusoidal Model, " M.S. thesis, Massachusetts Institute of Technology, August 2005. [5] T.J. Hazen, E. Saenko, C.H. La, and J. Glass, "A Segment-Based Audio-Visual Speech Recognizer: Data Collection, Development and Initial Experiments," Proc. of the International Conference on Multimodal Interfaces, October 2004. [6] A.P. Varga, H.J.M. Steeneken, M. Tomlinson, and D. Jones, "The NOISEX-92 Study on the Effect of Additive Noise on Automatic Speech Recognition," Tech. Rep., Speech Research Unit, Defense Research Agency, Malvern, U.K., 1992. [7] H.G. Hirsch and D.Pearce, "The AURORA Experimental Framework for the Performance Evaluations of Speech Recognition Systems under Noisy Condidions," in ISCA ITRW ASR2000 "Automatic Speech Recognition: Challenges for the Next Millennium", Paris, France, September 2000. |
|||
|