| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Optimizing Robot Trajectories using Reinforcement Learning
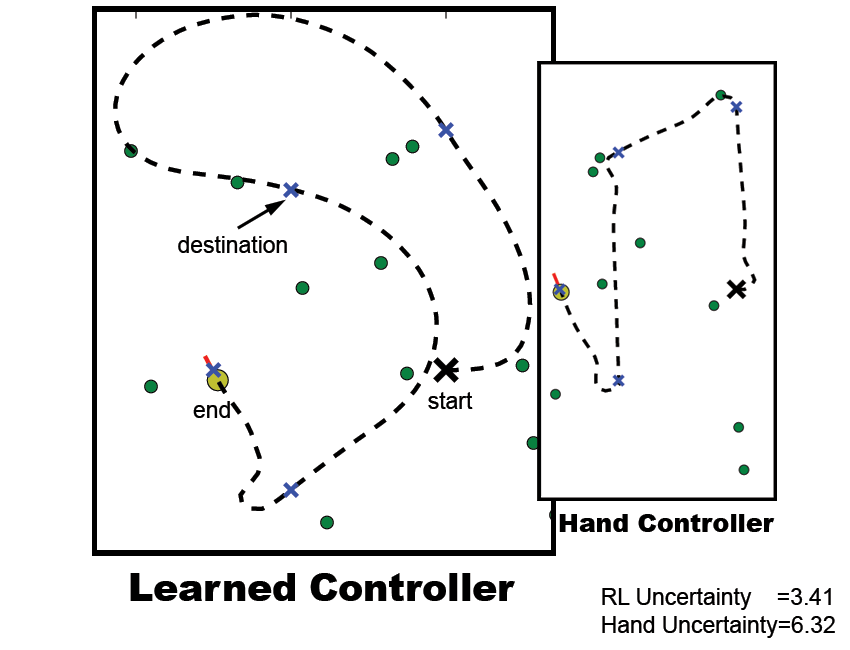
OverviewThe mapping problem has received considerable attention in robotics recently. Mature mapping techniques now allow practitioners to reliably and consistently generate 2-D and 3-D maps of objects, office buildings, city blocks and metropolitan areas with a comparatively small number of errors. Nevertheless, the ease of construction and quality of map are strongly dependent on the exploration strategy used to acquire sensor data. Most exploration strategies concentrate on selecting the next best measurement to take, trading off information gathering for regular relocalization. What has not been studied so far is the effect the robot controller has on the map quality. Certain kinds of robot motion (e.g, sharp turns) are hard to estimate correctly, and increase the likelihood of errors in the mapping process. We show how reinforcement learning can be used to generate better motion control. The learned policy will be shown to reduce the overall map uncertainty and squared error, while jointly reducing data-association errors.
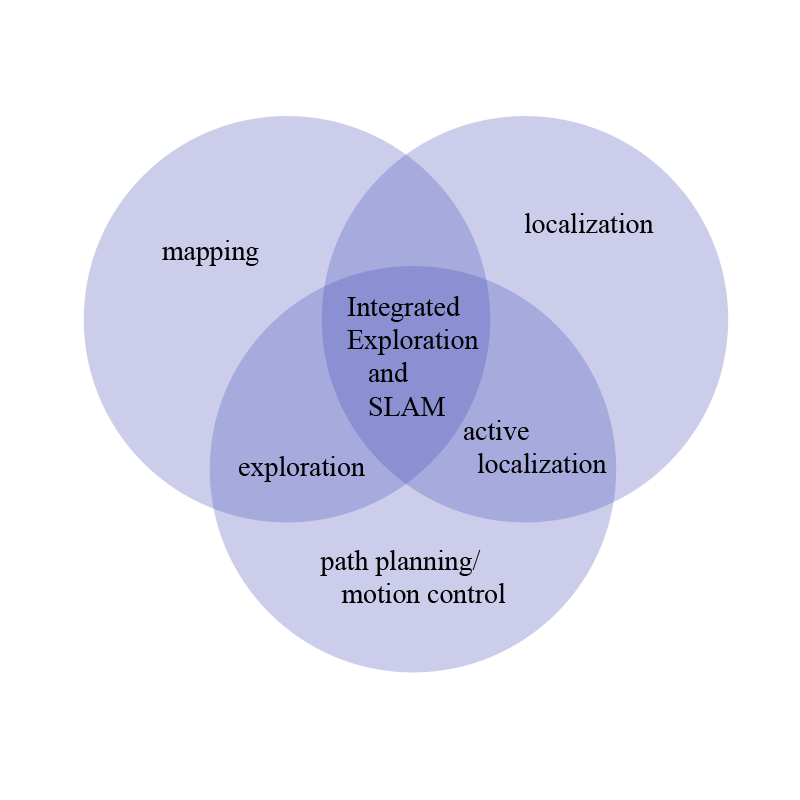
Problems addressedA particular area in which robotics has advanced significantly in the last few years is in the mapping problem. One of the remaining problems in mapping is how to choose motions during mapping that will positively impact map quality. This work focuses on how to integrate motion planning into the mapping process. By choosing trajectories during planning, we will show how to create better maps with a minimal number of errors. The creation of a map involves three components: mapping, localization and path planning, as indicated by Figure 2.
Each of these may be performed independently, and solves a useful problem in robotics. When a robot's pose is known precisely, mapping will be useful to identify obstacles and generate motion plans. When a map is known, then localization can provide information about the current location of the robot and given a destination can provide a path there. Given a map and a position then path planning can achieve a goal location. Though each of these can be performed independently, the joint execution of them will provide better approximations of uncertainty, better algorithms, and in the end, better maps. Not surprisingly, the most interesting aspects of creating a map come at the intersections of these problems. Combining path planning and localization begets active localization, where a robot will take actions to maximize its localizability. Combining mapping and path planning, a robot explores its world so a secondary goal is achieved (distance, time, coverage). Combining mapping and localization, a robot simultaneously estimates its position and the map by simultaneous localization and mapping (SLAM). The approach presented here is at the intersection of all three of these sets and is called the simultaneous planning, localization, and mapping (SPLAM) problem [8], where the robot will jointly take actions to make the best map possible as well as estimate its pose and the map. In general, we will use the shorthand exploration to encompass integrated exploration and SLAM.
ExplorationBuilding maps is one of the most fundamental problems in robotics. As operation times become longer and less structured environments become commonplace, the destinations and motion of the robot become critical for the acquisition of high quality sensory information and high quality maps. There are a number of objective functions that may be considered when building a map: time, power, coverage, and map accuracy are just a few. While distance and power consumed are factors that need to be taken into account, the most critical factor for many applications is acquiring a high-quality map. Optimizations with respect to time or coverage are only useful if the user will not spend hours editing poor scan alignments, pose estimates, or feature extractions, and the trajectory taken by the robot should be designed to lead to the best map in minimum time. For example, when creating 2D maps with wheeled mobile robots, certain kinds of robot motion (e.g, sharp turns) are hard to estimate correctly, and are known to increase the likelihood of errors in the mapping process. The exploration problem can be formalized as a belief-space Markov Decision Process (MDP), which will allow us to bring multistep policies to bear on our problem and thereby maximize long-term map accuracy. A policy for a MDP will give a mapping from robot and feature locations to an optimal action. A learned trajectory can be seen in Figure 3.
Related WorkThere are a number of objective functions that may be considered when building a map: time, power, coverage, and quality are just a few. While distance and power consumed are certainly factors that need to be taken into account, the most critical factor for many applications is acquiring a high-quality map. Optimizations with respect to time or coverage are only useful if the user will not spend hours editing poor scan alignments, pose estimates, or feature extractions. The first reward function is to minimize the unexplored area. In [9], the authors point the robot to the nearest unknown territory in hopes of exploring the entire world. The planning in this work is limited to choosing the nearest unexplored territory and does not factor in global distance or time. Another reward function is to take observations that make sure the robot sees all of the environment. This is closely related to the variants of the art-gallery problem, which will find the minimum number of locations that cover all surfaces [4]. This, however, requires a rough map beforehand. Also, both of these reward functions may produce poor quality maps in many situations, since map quality is not taken into account. A reward function that reflects the certainty of the map is reflected in the amount of information gained during the mapping process. This reward function will be one of the primary focuses of this thesis, along with the squared error. There is an abundance of related work using information gain for choosing actions, among which the most closely related comes from [6,8,3,7]. In [6,8], a weighted objective function is used that balances the amount of distance the robot will travel with the amount of information gain it will receive. The robot will then take the action which maximizes the myopic reward. Information-theoretic reward functions have also been used in a non-myopic manner to choose the next best measurement in sensor networks, with a number of interesting results [5]. This problem differs substantially from mobile-robot exploration in that and measurements cannot be taken at any time, but occur as the result of the robot pose.
ContributionsThe contributions of this work are four-fold. First, we will use a non-standard motion model developed in [2], and derive the relevant mean and covariance updates for the Extended Kalman Filter used for many of the experiments. Secondly, we will produce a characterization of the trajectory exploration problem, which to our knowledge has not been considered before in this context and will discuss the properties of the determinant and trace as optimization metrics. Third, we discuss the formalization of the trajectory exploration problem as a belief space Markov Decision Process, and why this formalization makes sense. Finally, we will show how to solve this problem with a particular policy search method [1] and give experimental results. Bibliography[1] James Bagnell, Sham Kakade, Andrew Ng, and Jeff Schneider. Policy search by dynamic programming. In Neural Information Processing Systems, volume 16. MIT Press, December 2003. [2] A. Eliazar and R. Parr. Learning probabilistic motion models for mobile robots, 2004. [3] H. Feder, J. Leonard, and C. Smith. Adaptive mobile robot navigation and mapping, 1999. [4] Hector Gonzalez-Banos and Jean-Claude Latombe. Planning robot motions for range-image acquisition and automatic 3d model construction. [5] Andreas Krause, Carlos Guestrin, Anupam Gupta, and Jon Kleinberg. Near-optimal sensor placements: maximizing information while minimizing communication cost. In IPSN '06: Proceedings of the fifth international conference on Information processing in sensor networks, pages 2-10,New York, NY, USA, 2006. ACM Press. [6] A. Makarenko, S. Williams, F. Bourgault, and H. Durrant-Whyte. An experiment in integrated exploration, 2002. [7] Robert Sim. On Visual Maps and their Automatic Construction. PhD Thesis, 2006. [8] C. Stachniss. Exploration and Mapping with Mobile Robots. PhD thesis, University of Freiburg, Department of Computer Science, April 2006. [9] B. Yamauchi. A frontier based approach for autonomous exploration, 1997. |
|||||
|