| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
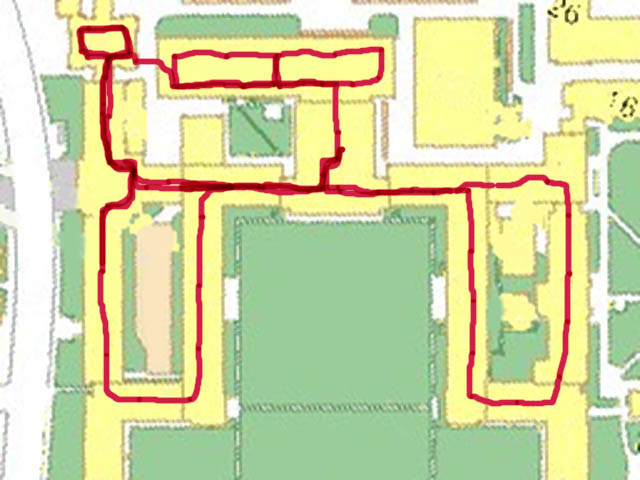
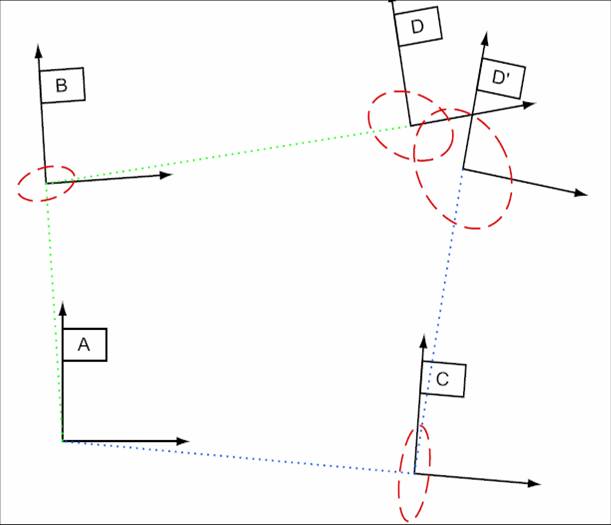
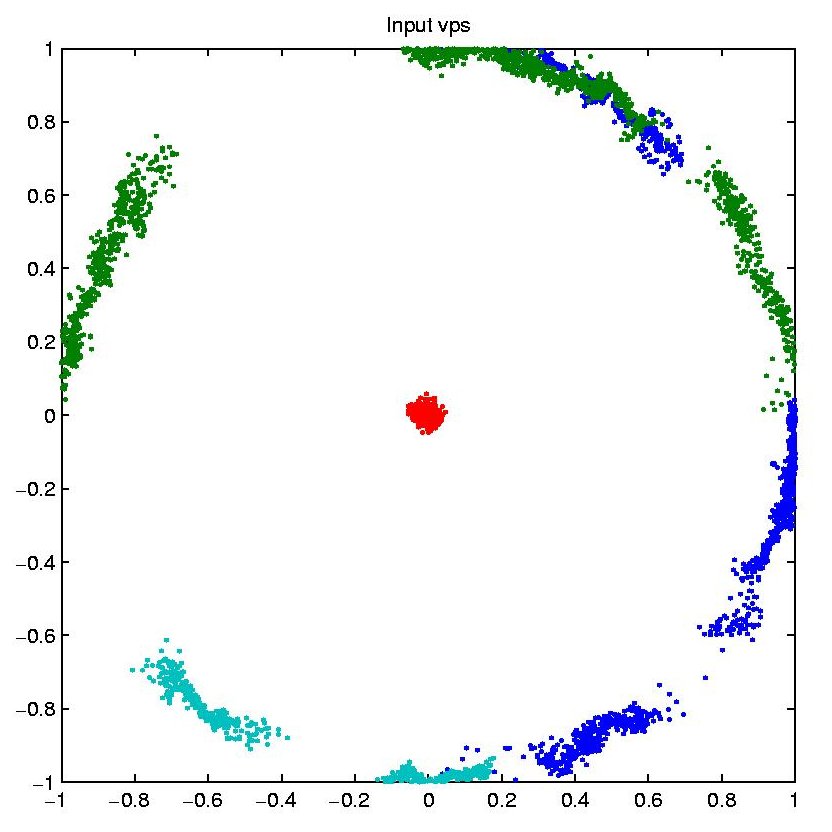
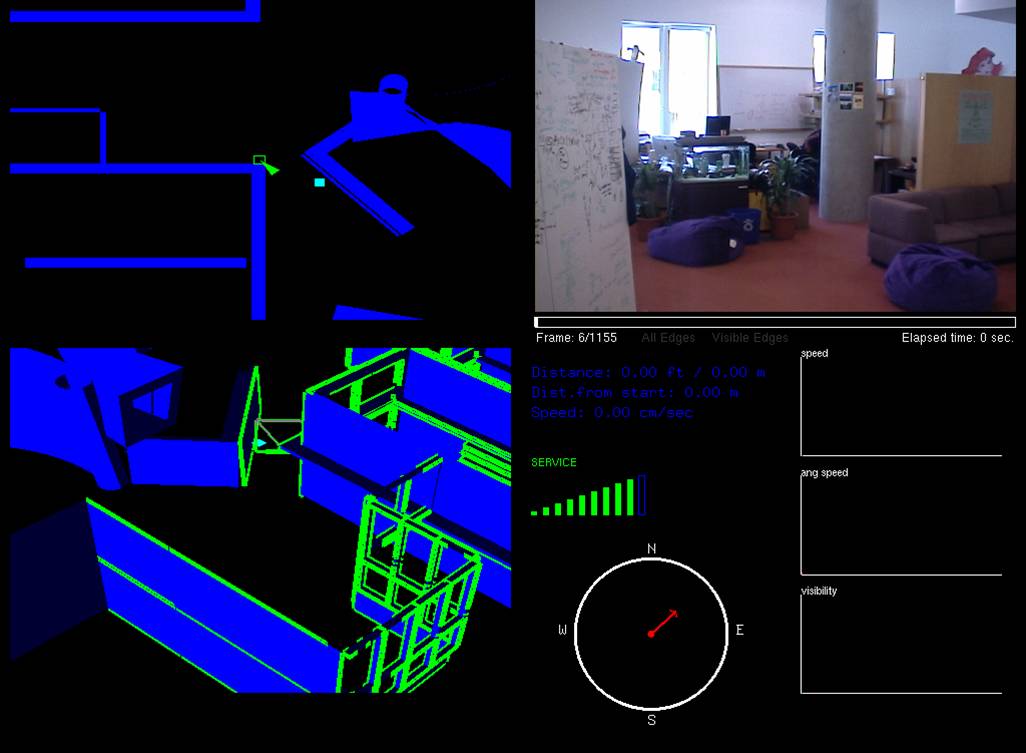
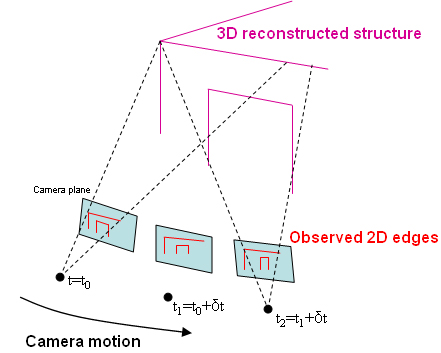
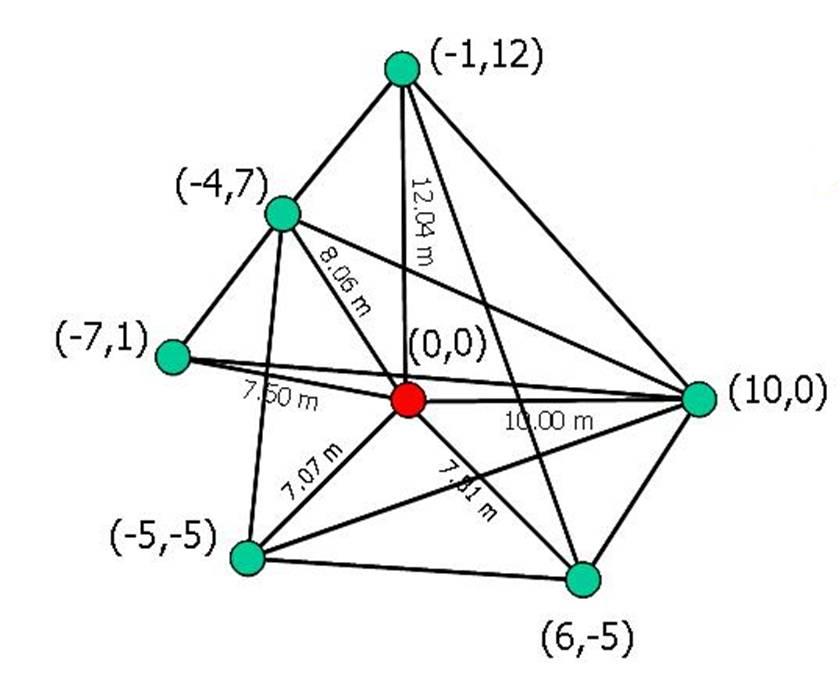
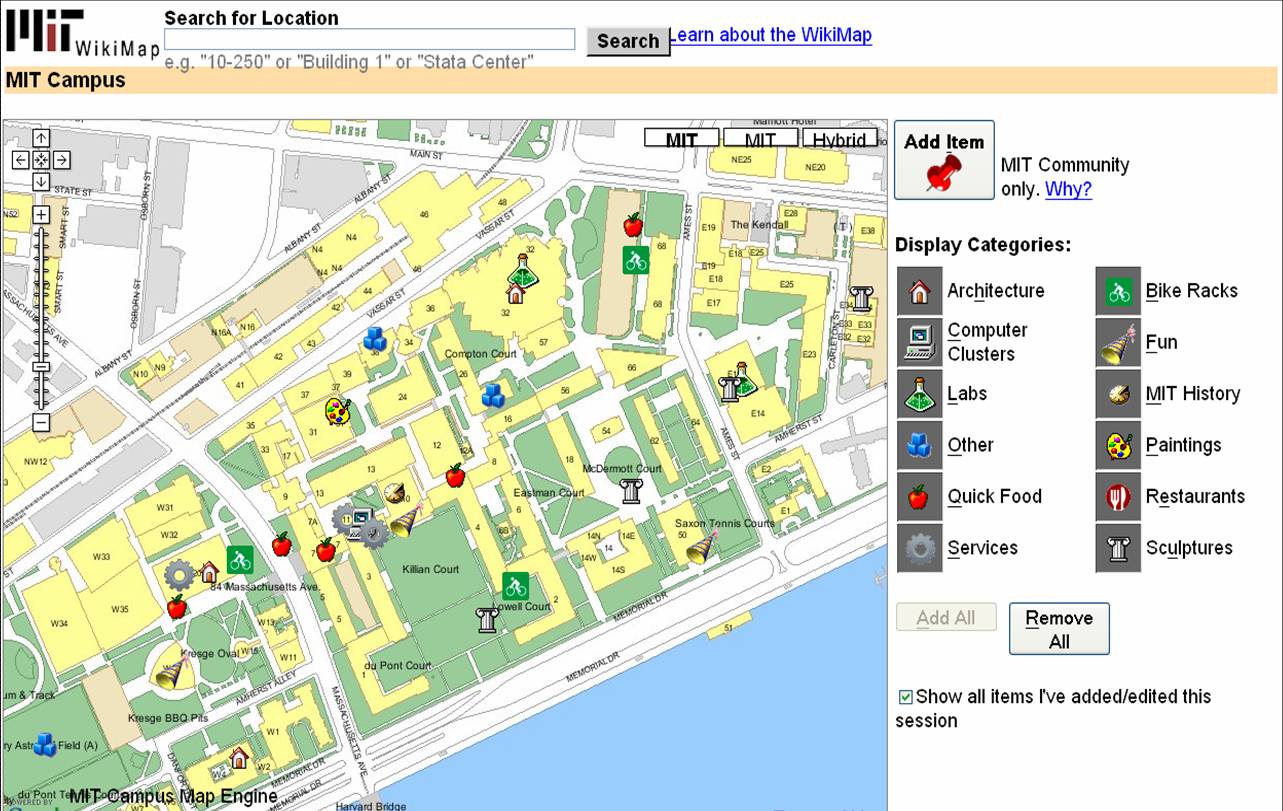
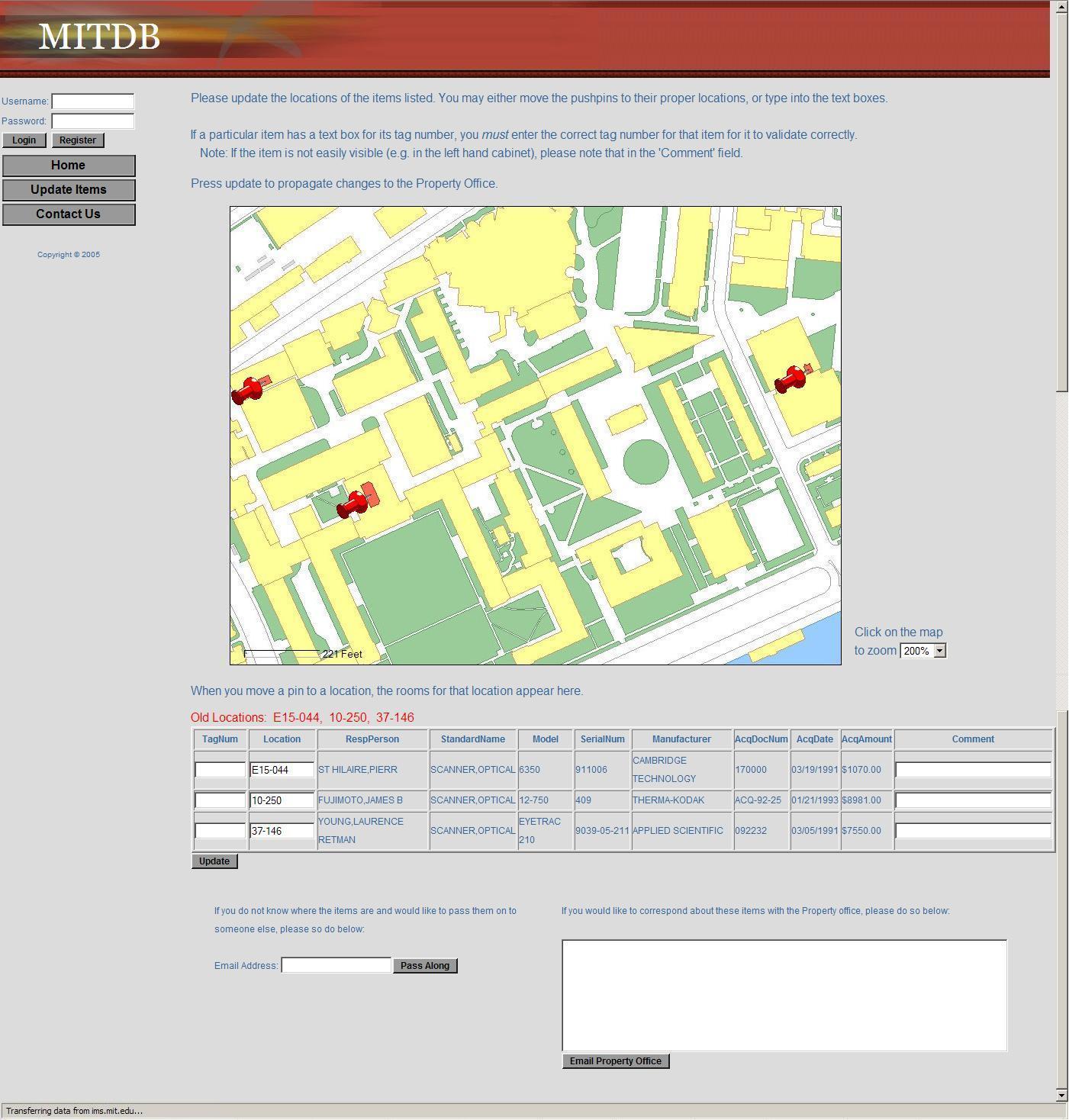
Semantic Environment Capture, Fine-Grained Localization, and ApplicationsSeth TellerOverviewThe Robotics, Vision, and Sensor Networks group (RVSN) develops techniques for capturing geometric, topological, and semantic environment models (Figure 1); fine-grained localization within such models (Figure 2); and building upon model capture and localization to achieve novel and useful capabilities and applications (Figure 3) to assist with both human and robotic tasks. Capability ScenariosImagine a guide, in the form of an accompanying robot or a hand-held device, that could prevent you from becoming lost, even in a complex, unfamiliar indoor environment. The guide could lead you to your host's office; to a conference room; to the nearest bathroom, kitchen, copier or printer; or, in the event of emergency, along a safe route to the nearest exit. Imagine that the guide could understand commands and questions in human terms, e.g., "Take me to Steve's office," rather than machine terms, e.g., "Take me to (x,y,z)." Imagine a group of people (e.g., a hazardous materials response team) about to enter an unfamiliar and possibly dangerous space. The group could deploy an advance team of small autonomous robots to explore and map the environment, relaying the map and other sense data to the trailing humans as it is constructed. Once inside, the humans could flag specific locations or objects as dangerous, or safe, simply by pointing at them and uttering a keyword. Imagine making a maintenance request to MIT's Department of Facilities, or a suspicious activity report to the MIT Police, simply by pointing your device in the direction of the problem. Speaking or typing your observations would attach a metadata annotation or "virtual tag" to the indicated location in a persistent database. The responding maintenance engineer or police officer would have ``X-ray vision'' in the form of an annotated image, displayed on the device or projected by the device onto an opaque wall, representing the infrastructure (e.g., studs, ducts, wiring) within the wall, or activity (e.g., people's locations and movements) beyond the wall. In a fire emergency, an analogous display within the protective hoods of responding fire-fighting personnel would enable efficient navigation within the emergency zone, even with ordinary vision degraded by fire or smoke. Imagine a device or robot speech capability that could understand the user's references to places and objects in the environment, in human terms: ``Bill's desk;'' ``the kitchen;'' ``in front of me.'' Imagine dynamic, programmable signs placed densely throughout MIT that in ordinary circumstances would display announcements of imminent lectures and talks, tailored to each sign's location. In emergencies, the signs would reconfigure themselves to display evacuation routes, using timely sensor network data to avoid recommending impassable or unsafe routes. Imagine robots deployed for the purpose of maintaining a current, as-built geometric and topological map of a region. If during periodic return visits the robots detected change (due to construction, demolition, renovation etc.) they would revise the map. A team of robots with extended capabilities could be deployed to an unprepared, remote site (e.g., Iraq, Mars) to survey the site and erect a facility for the use of later-arriving humans. Prototype Devices, Algorithms, and SystemsWe have developed a number of devices, algorithms, and demonstrated prototype systems in and around MIT, in support of the capabilities described above. To support model capture, we have investigated a number of algorithms for SLAM, or simultaneous localization and mapping. In the "geometric" version of SLAM, a sensor suite moves through an environment (carried by a human or a robot), and associated algorithms generate a map of the environment, and an estimate of the sensor suite's path through the environment. We have demonstrated SLAM in terrestrial environments using acoustic and laser ranging [3], and machine vision [9]; we have also demonstrated SLAM underwater in a field of acoustic transponders (ranging beacons) [5]. Finally, we have independently produced ground-truth 3D CAD models of extended environments [27] in order to evaluate our methods. One major focus of our work has been to develop scalable SLAM methods capable of producing maps from very long excursions through complex spaces [3], ideally in real-time so that the generated map can be used as a basis for on-line decision making [12]. We have recently extended these methods to handle loop-closing in very large environments [25]. We are also investigating the development of "semantic" SLAM methods, to produce maps with not only geometric and topological aspects, but also attributes such as labels with meaning to humans. We have developed a prototype semantic SLAM system in which the human user provides a stream of gestures and utterances indicating and describing places and objects within the environment [11]. We have recently extended this work to enable a small mobile robot to accept textual commands (e.g. "Go to the conference room") and react by moving to the commanded region [19]. The efforts referenced above assume a static (i.e., unchanging) world. But the world does change over time, and another technical challenge is to develop robotic systems that can account for and represent change. We are developing "change detection" methods through which sensor suites, when repeatedly traversing the same environment, can detect and flag changes in the appearance of the environment [17]. The most recent thread of our work in this regard is the development of "persistent tracking" methods for video, in which objects can be tracked for long periods as they appear within the field of view of a moving camera [15]. A map is far more useful when its (human or robot) user can localize, or determine its position and orientation, with respect to the map. We have developed a prototype localization method based on omnidirectional video captured within an environment whose crude structure is known [14]. This should enable us, in principle, to estimate a human's or robot's fine-grained "pose" (position and orientation) at 30 Hz for most locations within spatially extended environments. This localization capability is not currently achievable within complex indoor regions by any means other than painstaking manual surveying. Finally, we are developing a number of applications of mapping and localization. We have demonstrated in situ environment annotation, and augmented reality systems that overlay metadata directly onto environment surfaces (using a projector) rather than onto a head-mounted display [10]. We have deployed a prototype system for in situ construction of as-built (rather than as-planned) CAD models [18]. We have deployed prototype mapping robots and sensor suites in a number of indoor, outdoor, and underwater settings [1,2,3,5,11]. We have developed a change detection system in which a human "sequence analyst," analogous to an "image analyst," is presented with the results of video-based change detection and asked to characterize flagged difference regions as true or false positives [17]. We have developed a prototype navigation assistant based on localization from worn or carried omnidirectional video camera [14, 24]. We have deployed a self-configuring network of Cricket beacons that functions much like an an "indoor GPS" system, providing location information to people or mobile robots [4,13]. This work has been extended to the all-nodes-moving case [21]. A variant of this work is a "mobile-assisted" localization method, in which a human installer provides mobility to a measurement unit that moves within an otherwise fixed sensor field, enabling the fixed sensors to localize themselves [7]. We have sought to develop natural speech interfaces to information applications and mobile robots. We have developed a prototype "speech calendar" meant for use by all family members in the home [22]. Finally, we have developed a number of tools for organization, visualization, and collaborative modification of location-based data [16, 23, 27, 28]. Our "wikimap" combines aspects of maps and wikis (web pages produced by collaborative editing), enabling users to add fine-grained, geo-referenced tags to the MIT campus map. Our "asset tagging" application semi-automates the process of tracking the locations of MIT assets as they are delivered, used in laboratory and teaching spaces, and eventually decommissioned. Both tools are currently used at a distance, as web applications. However we plan to extend them to in situ usage so that users can interact directly with a soft-copy representation of the environment from anywhere within it (rather than only while sitting at their desks). DARPA Urban Challenge:Teller is the Perception Team Lead for MIT's entry into the 2007 DARPA Urban Challenge, the goal of which is to develop an autonomous passenger vehicle capable of safe driving in urban traffic (the 2007 competition has no pedestrians). The Perception Team's responsibility is to localize the car within the provided road network, and provide awareness of the car's surroundings (road surface, lane markings [20], road hazards, other vehicles) to the car's Planning, Control, and Safety layers. One novel aspect of our approach is a "ground-truth" marking tool [26] with which we manually mark lanes, hazards, other vehicles, etc. in logged video, then compare our various detectors' outputs to the ground truth outputs to assess detector performance. References:[1] E. Olson, J. Leonard, and S. Teller, Fast Iterative Alignment of Pose Graphs with Poor Initial Estimates. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation (to appear), Orlando FL, May 2006. [2] E. Olson, M. Walter, J. Leonard, and S. Teller, Single Cluster Graph Partitioning for Robotics Applications. In Proceedings of Robotics: Science and Systems Conference, pp. 265-272, Cambridge MA, June 2005. [3] M. Bosse, P. Newman, J. Leonard, and S. Teller, Simultaneous Localization and Map Building in Large-Scale Cyclic Environments Using the Atlas Framework. In International Journal of Robotics Research 23(12), pp. 1113-1139, December 2004. [4] D. Moore, D. Rus, J. Leonard, and S. Teller, Robust Distributed Network Localization with Noisy Range Measurements. In Proceedings of the Second ACM Conference on Embedded Networked Sensor Systems (SenSys '04), pp. 50-61, Baltimore MD, November 2004. [5] E. Olson, J. Leonard, and S. Teller, Robust Range-Only Beacon Localization. In Proceedings IEEE AUV (Autonomous Underwater Vehicles: Workshop on Multiple AUV Operations), pp. 66-75, Sebasco Estates ME, June 2004. [6] P. Sand and S. Teller, Video Matching. in Proceedings ACM SIGGRAPH, 22(3), pp. 592-599, Los Angeles CA, August 2004. [7] N. Priyantha, H. Balakrishnan, E. Demaine, and S. Teller, Mobile-Assisted Localization in Wireless Sensor Networks. in Proceedings IEEE InfoCom, pp. 172-183, Miami FL, March 2005. [8] P. Sand and S. Teller, Particle Video. In Proceedings Computer Vision and Pattern Recognition (to appear), Boston MA, July-August 2006. [9] M. Bosse, R. Rikoski, J. Leonard, and S. Teller, Vanishing Points and 3D Lines from Omnidirectional Video. in The Visual Computer (Special Issue on Computational Video) 19(6), pp. 417-430, October 2003. [10] J. Chen, H. Balakrishnan, S. Teller, Pervasive Pose-Aware Applications and Infrastructure. In IEEE Computer Graphics and Applications 23(4), pp. 14-18, July/August 2003. [11] A. Huang and S. Teller, Machine Understanding of Narrated Guided Tours, CSAIL Research Abstract, March 2006. [12] E. Olson, J. Leonard and S. Teller, Fast and Robust Optimization of Pose Graphs, CSAIL Research Abstract, March 2006. [13] D. Moore, J. Leonard, D. Rus and S. Teller, Robust Distributed Network Localization and Uncertainty Estimation, CSAIL Research Abstract, March 2006. [14] O. Koch and S. Teller, Fine-Grained 6-DOF Localization from Known Structure, CSAIL Research Abstract, March 2006. [15] P. Sand and S. Teller, Particle Video, CSAIL Research Abstract, March 2006. [16] J. Battat, G. Giovine, E. Whiting, and S. Teller, A Robust Geospatial Data Framework and Federation Mechanism for Modeling and Navigating Local Environments, CSAIL Research Abstract, March 2006. [17] J. Velez and S. Teller, An Environmental Change Detection and Analysis Tool Using Terrestrial Video, CSAIL Research Abstract, March 2006. [18] R. Baliga, Rapid Coordinate System Creation and Mapping Using Crickets. Master of Engineering Thesis, MIT, 2004. (Video) [19] A. Huang and S. Teller, Non-Metrical Navigation Through Visual Path Control, CSAIL Research Abstract, March 2007. [20] David C. Moore, John Leonard & Seth Teller, Perception and Navigation for the DARPA Urban Challenge, CSAIL Research Abstract, March 2007. [21] Jun-geun Park, Erik D. Demaine, & Seth Teller, Moving-Baseline Localization, CSAIL Research Abstract, March 2007. [22] Xin Sun & Seth Teller, A Prototype Speech Calendar, CSAIL Research Abstract, March 2007. [23] Yoni Battat & Seth Teller, A Framework for Extracting, Modeling, and Accessing Fine-Grained Geometric, Topological, and Semantic Features of Campus Spaces, CSAIL Research Abstract, March 2007. [24] Olivier Koch & Seth Teller, Wide-Area Egomotion From Omnidirectional Video and Coarse 3D Structure, CSAIL Research Abstract, March 2007. [25] Edwin Olson, John Leonard & Seth Teller, Map Building in Difficult Environments, CSAIL Research Abstract, March 2007. [26] Geoff Wright & Seth Teller, Construction and Use of Ground Truth Tool for Drivezone, Lane Marking, and Hazard Classification in Roadway Video, CSAIL Research Abstract, March 2007. [27] Xiao Xiao & Seth Teller, Ground-Truth, As-Built 3D CAD Model of Stata Center, CSAIL Research Abstract, March 2007. [28] Dmitry Kashlev & Seth Teller, Shared Spaces and Edges in Distributed Geometric Building Models, CSAIL Research Abstract, March 2007. |
|||
|